前言
我们都知道Redis是直接将数据存储在内存里面着,但是一般我们的内存的容量是有限的,小则一两个G,最多也就十多个G,而且内存都很贵,在数据量大的话导致Redis服务器的内存严重不足,是非常头疼的事,要么加内存解决,要么使用集群解决,两者都会引起资金上的开销。我们可以使用另一种方法来降低Redis存储数据的空间,以此来降低内存的开销,解决内存不足的问题。本篇博客主要讲解 短结构 和 分片技术(sharding) 。
短结构
Redis默认为列表、集合、散列和有序集合提供了一种配置,当这四种结构存储的数据不是很大时,Redis使用更加节约空间的方式存储数据,这种结构称为 短结构 。
在列表、散列和有序集合的长度较短的时候,Redis会选择一种名为 压缩列表(ziplist) 来存储(集合是另一种形式,等下再说)。通常情况下Redis使用双链表表示列表、使用散列表(类似于HashMap)表示散列、使用散列表加跳跃表(skiplist)表示有序集合的做法不同,压缩列表会以序列化的方式存储数据,这些序列化数据每次被读取的时候都需要进行解码,写入的时候也要局部重新编码,并且可能会对内存中的数据进行移动。
当存储的列表过长时,就会使用双向链表,比如列表中有”one”,”two”,”ten”这三个值,存储形式如下图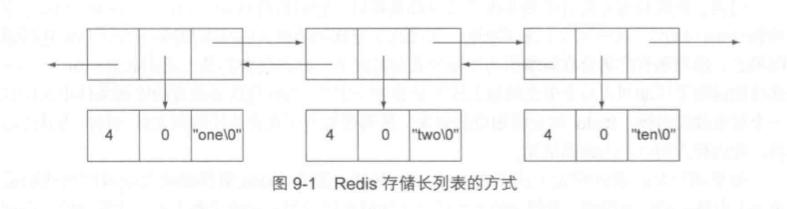
前面的4表示存储的字符创的长度,0表示存储字符串值中剩余可用的字节数量,最后一部分就是字符串本身,除此之外剩余的就是指针的存在,因此,指针带来了额外的开销。在32位平台上,每存储这样3字节长的字符串,需要付出21字节的额外开销。
而压缩列表由节点组成的序列(sequence),每个节点都由两个长度值和一个字符串组成。长度值记录前一个节点的长度(这样当下一个节点需要读取上一个节点的值时,因为空间是连续的,直接通过长度就可读取上一个节点的值),第二个长度值记录当前节点的长度,最后存储字符串。
在redis.conf配置文件中,就有规定在数据大小多大的范围内使用短结构(压缩列表不是越长越好)1
2
3
4
5
6
7
8
9
10
11# Hashes are encoded using a memory efficient data structure when they have a
# small number of entries, and the biggest entry does not exceed a given
# threshold. These thresholds can be configured using the following directives.
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
# Similarly to hashes and lists, sorted sets are also specially encoded in
# order to save a lot of space. This encoding is only used when the length and
# elements of a sorted set are below the following limits:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
上面规定了hash或者zset的大小超过64字节或者元素超过规定的大小时,就会从压缩列表转变为原来的数据结构(这里没有给出list列表的规定原因是:新的Redis中已经更改了list压缩列表的条件,但是我还不是很懂规定的形式,所以没贴出来),而且要注意, 如果从压缩列表转变为普通的数据结构比如转变为双向列表,即使后面把双向列表的大小减小到小于64字节,也不能够重新转变为压缩列表,也就是说转变是不可逆的
集合的整数编码
上面之所以没有提到集合,是因为集合跟上面三种数据结构不同,但是体积较小的集合也还是有自己紧凑形式表现,Redis就会以有序集合整数的形式存储集合,称为 整数集合(intset)
redis.conf中作了这样的限制1
2
3
4
5
6# Sets have a special encoding in just one case: when a set is composed
# of just strings that happen to be integers in radix 10 in the range
# of 64 bit signed integers.
# The following configuration setting sets the limit in the size of the
# set in order to use this special memory saving encoding.
set-max-intset-entries 512
并不是说压缩列表或者整数集合越大越好
当一个结构突破了用户为压缩列表或者整数集合设置的限制条件时,Redis就会自动将它转换为更为经典的底层数据结构,这样做的主要原因在于,随着紧凑结构的体积越来越大,操作这些结构的速度就会越来越慢。
主要将压缩列表的长度限制在500~2000个元素内,并将每个元素的体积限制在128字节或以下,那么压缩列表的性能就会处于合理范围之内。
压缩列表一般要配合分片结构才能发挥降低内存的作用
分片结构
分片是基于某种简单的规则将数据划分为更小的部分,然后根据数据所属的部分来决定将数据存储到哪个位置上,很多集群时的数据可以通过分片结构将数据平分到不同的Redis服务器上
比如当我们有一个很大的Hash结构时,里面的数据只是一个简单的key-value,你可以想象成 学号-姓名的对应,这个Hash里面存储了上万条数据(学号是唯一的),这样的话Redis底层的就不是用压缩列表存储了,因为数据大小已经远远超过了entry或者size了。
这个分片结构就派上用场了,我们可以把里面的key-value平分到多个Hash结构上,使每个Hash的大小都不超过entry和size的规定,这样每个Hash就还是压缩列表的结构。
这种实现方式也很简单, 只要设置预计元素的总数量以及请求的分片数量,然后对键通过算法进行计算,得出这个键应该存储在哪个位置即可。
java———使用Jedis1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public String shardKey(String base, String key, long totalElements, int shardSize) {
long shardId = 0;
// 判断是否为整数
if (isDigit(key)) {
shardId = Integer.parseInt(key, 10) / shardSize;
}else{
// 如果不为整数,通过CRC32算法计算出该键的模来得出位置
CRC32 crc = new CRC32();
crc.update(key.getBytes());
long shards = 2 * totalElements / shardSize;
shardId = Math.abs(((int)crc.getValue()) % shards);
}
return base + ':' + shardId;
}
public Long shardHset(
Jedis conn, String base, String key, String value, long totalElements, int shardSize)
{
String shard = shardKey(base, key, totalElements, shardSize);
return conn.hset(shard, key, value);
}
public String shardHget(
Jedis conn, String base, String key, int totalElements, int shardSize)
{
String shard = shardKey(base, key, totalElements, shardSize);
return conn.hget(shard, key);
}
java——使用RedisTemplate1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public String shardKey(String base, String key, long totalElements, int shardSize) {
long shardId = 0;
CRC32 crc = new CRC32();
crc.update(key.getBytes());
long shards = 2 * totalElements / shardSize;
shardId = Math.abs(((int)crc.getValue()) % shards);
return base + ':' + shardId;
}
public void shardHset(
String base, String key, String value, long totalElements, int shardSize)
{
String shard = shardKey(base, key, totalElements, shardSize);
redisTemplate.opsForHash().put(shard, key, value);
}
public String shardHget(
String base, String key, int totalElements, int shardSize)
{
String shard = shardKey(base, key, totalElements, shardSize);
return (String) redisTemplate.opsForHash().get(shard, key);
}
实现的方式其实挺简单的,就是通过求键的模,通过不同的模把数据存储到不同的Hash中。
集群也是同样的道理,将不同的模的数据存储到不同的服务器,比如模0~4存储到1服务器,其他存储到2服务器