Redis为什么这么快?
- 1、纯内存操作:我们的数据都是存储在内存中的,所以跟存储在硬盘相比,写入读取速度快很多倍
- 2、丰富的数据结构:redis基础的五种数据结构(string、hash、list、set、zset)是我们日常使用存储数据的结构(当然还有其他的结构,比如geo、hyperloglog),这些结构的性能非常优越,比如基础数据结构(除了set),刚开始是用压缩列表的结构存储数据,不仅读取速度快,而且占用内存也少。 (关于压缩列表可以查看,通过优化降低Redis的内存占用 这篇博客)
- 3、I/O多路复用模型——本篇博客就是为了讲解这个模型
- 4、单线程操作:减少多核CPU上下文切换引起的开销
Redis的IO多路复用模型
借助网上的例子说明情况:比如有很多个水龙头(就是我们客户端的请求),但这些水龙头都不知道什么时候来水。当水来的时候,要把这些水接住,所以需要人(redis的线程)负责,但是我们需要多少个人?难道要每个水龙头都站一个人?这样的话当请求很多时,创建很多线程,肯定内存不够用。所以Redis采用一个线程(相当于一个人)来循环试探这些水龙头,当拧开水龙头发现有水时就处理。
I/O多路复用模块是操作系统底层的东西,进程只要告诉操作系统需要监听哪个端口的Socket,当这些端口有套接字的可读或可写(Socket)事件时,操作系统就会通知进程(Redis)。而I/O监听这些端口,就是使用select ,poll ,epoll ,kqueue 这些I/O多路复用函数。这些函数可以同时监控多个流的I/O事件能力,如果没有Socket连接(没有请求过来时)的时候,当前主线程会阻塞;当有一个或者多个流过来时,操作系统就会通知程序(Redis),Redis就会轮询一遍所有的流,对这些流进行处理,这过程是有顺序的,先来先服务FIFS。所以“多路”指的是有多个请求连接,“复用”指的是复用一个线程,这个线程负责把请求监听请求,当有请求到来时,就传递给程序处理。这样的模型,提高了单个线程的处理能力,一个线程就可以高效的处理多个连接请求,尽量减少网络IO的开销 。
跟传统的阻塞IO相比,在计算机网络中,我们的请求可能被分成许多包,经过不同的路由器传递,如果有些包到达了服务器,有些还没到,那么服务器就要等到这些包全都收集齐了才能处理。如果请求很多,那么等待的时间就会很长,这就是网络开销之一。如果使用IO多路复用模型,把监听这些包有没有准备好的事情交给操作系统,我们只需调用轮询api(select、poll、epoll..)不断的询问操作系统就行了。当没有请求或者请求还没准备好时,Redis就可以做其他事情。
来看张图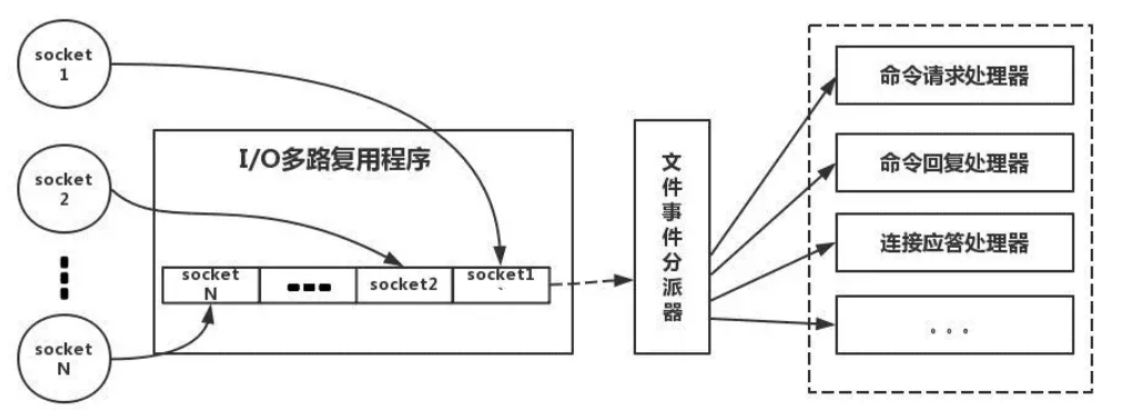
在Linux中,Socket也是文件!
类似上面的例子,当有很多请求到来时(一个Socket就相当于一个请求),操作系统就会跟踪这些请求 ,而且是有顺序的存入,先来先服务FIFO的原则。接下来,文件事件分配器 循环扫描指令队列,将不同类型请求的Socket交给不同的处理器(比如有些请求时get、有些是set)。循环扫描的过程就叫事件轮询 ,这种事件轮询是操作实现的,常见的事件轮询api有:select ,poll ,epoll ,kqueue 。
select是最早出现的多路复用api,但是有一些缺点,比如最大只能有1024个线程,线程不安全;接着poll就修复了select的一些问题,解决了1024的问题,但还是线程不安全;最后epoll出现了,他解决了select的所有问题,现在的Linux都是使用它完成多路复用模型,但epoll只能在Linux上实现。kqueue是macos系统的东西。