前言
好久没写博客了,今天就来写一篇跟排序算法有关的博客
说到排序算法,首先想到的有快排,堆排序等优秀的算法,你知道排序算法有哪些分类吗?
一、内排序、外排序
内排序:指数据直接在内存中进行,无需借助外存
外排序:由于数据量太大,内存不能一次性装完,需要借助外存储器才能完成
其实对于外排序,处理的时候大多数也会使用到内排序,也就是将一部分数据从磁盘加载进来然后使用内排序完后再写回磁盘
但也有直接外排序的算法,比如:多路平衡归并排序,置换——选择排序,最优归并树(PS:这些都没了解过hhhh)
但是常见的内排序算法就有很多了:冒泡、选择、插入、希尔、归并、快速、堆排序、计数排序、桶排序这些都是常见的排序算法
二、稳定性
何为稳定性?
比如这样: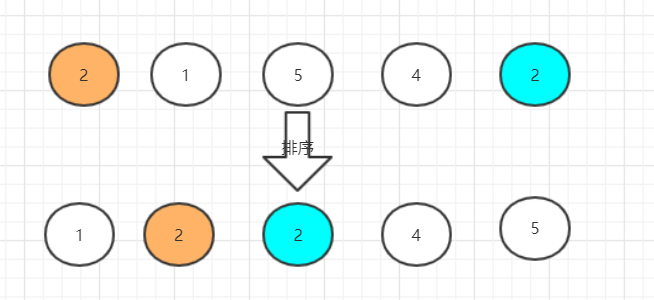
还没排序前,橙色的2在蓝色的2前面
排完序后橙色的2还是在蓝色的2前面
如果能做到这种特性,那么就认为该排序算法是稳定的
为什么需要稳定的排序算法呢?
因为有时候我们不止依赖一个特性来排序,比如订单有金额跟下单时间的特性,我们按金额大小排序,如果金额相等,就要求按下单时间来排序。如果要求你来做,你怎么实现呢?
如果有稳定的排序算法,我们可以先按下单时间来排序,拍完后就再按照金额来排序,这样就能符合我们如果金额相等就按下单时间来排序
因为先按时间排好序后,再用稳定的排序算法按金额排列,不会出现相等金额的时间乱序的情况
稳定性的排序算法有:冒泡排序、插入排序、归并排序、希尔排序
不稳定的排序算法有:选择排序、快速排序
三、是否需要辅助空间
不需要申请额外内存的排序,也叫做原地排序,常见的原地排序算法有:冒泡、选择、插入、希尔、快速、堆排序
而向归并、桶排序、计数排序,它们虽然时间复杂度很快,但需要借助额外的内存空间
所以选择合适的排序算法的时候,也需要考虑是否需要额外的内存空间,比如你的内存只有2G,但你有1.5G的数据需要排序,你得考虑申请额外空间是否够用
四、平均时间复杂度
O(n^2):冒泡排序、选择排序、插入排序
O(nlog2n):希尔排序
O(nlogn):归并排序、快速排序、堆排序
O(n):计数排序、桶排序
也许有人会问,竟然计数跟桶排序能做到O(n)的时间复杂度,为什么他们不会经常出现在我们的视野呢?而是快排或者堆排序出现的比较多?
你学下去不就知道了
下面分析的时间复杂度都是平均时间复杂度
冒泡排序
冒泡的思想为:每次比较相邻的元素。如果第一个比第二个大,交换他们,然后按照这个思想往后遍历
每次遍历完,最后的元素都是最大的
看一下经过一次冒泡排序后,数据经过了哪些改变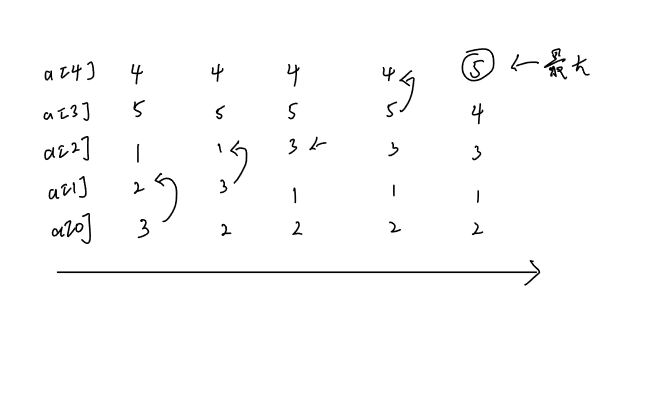
可以看到,无序的数据经过一次冒泡后,5作为最大的数据被排在了末尾
再看一下完整的过程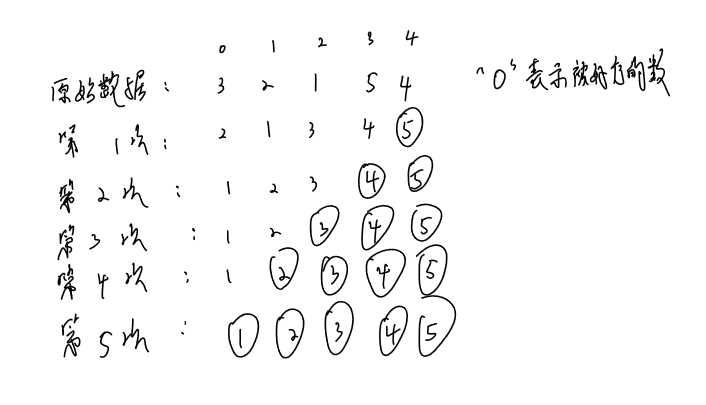
可以看到冒泡的每一次操作都能从中将最大的数移动到末尾,这样最后的数据就是有序的了
代码实现:
1 | package sort_alorgithm; |
上述代码中,加入了一个boolean类型的flag,为了减少循环的次数,如果遍历的过程中发现没有数据交换,那么就可以认定为该组数据已经有序,后面的操作都不用做了,直接跳出
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定排序
选择排序
思想:每次遍历数据,从中选出最大的数(最小也可以),换到数据末尾
代码实现:
1 |
|
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:非稳定排序
插入排序
你应该玩过扑克牌,当你开始整理你的牌的时候,那你可能习惯一张一张的抽出牌并把它插入到正确的位置,插入排序的思想正是如此
从前往后遍历数据,以第一个数据为基准有序数据,将数据插入到正确的位置
其实实现的时候,插入是指将前面的数据比目前该数据大的往后移动,腾出空间插入
代码实现:
1 | package sort_alorgithm; |
时间复杂度:O(n^2)
空间复杂度:O(1)
稳定性:稳定排序
希尔排序
希尔排序是对插入排序的改进,有实验证明,如果数据时部分有序的数据,使用插入排序效率会很高,所以希尔排序就是在这点上改进来的
针对插入排序的两点性质而提出的改进方法:
1、 插入排序在对几乎已经排好序的数据操作时,效率高,可以达到线性排序的效率
2、 但插入排序一般来说效率是低效的,因为每次插入排序每次只能将数据移动一位
希尔排序的基本思想:
将待排序的记录分割成为若干个子序列,分别进行插入排序,待整个序列记录“基本有序时”,再对整体进行插入排序
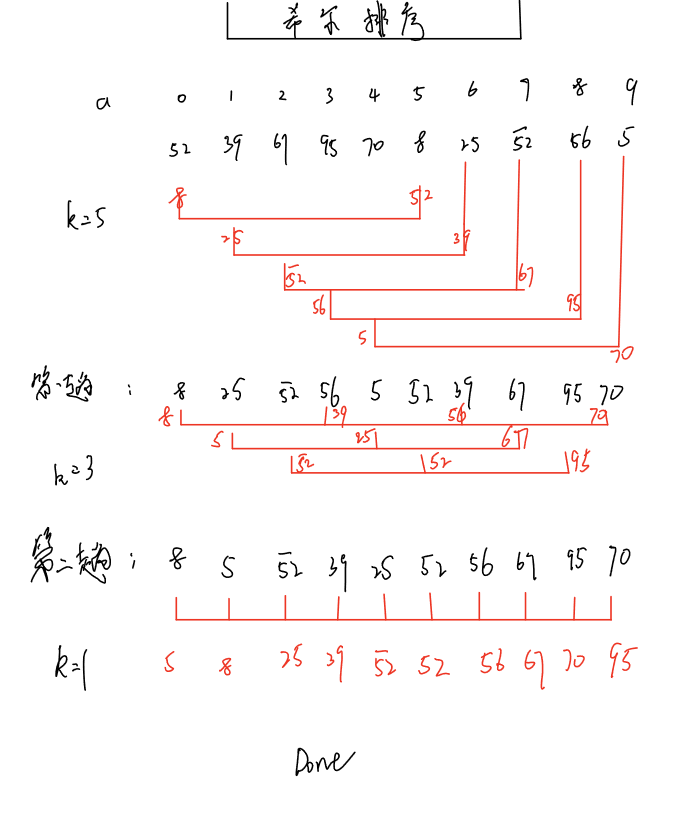
代码实现:
1 | package sort_alorgithm; |
时间复杂度:O(nlog2n)
空间复杂度:O(1)
稳定性:非稳定排序
总结
今天聊了冒泡、选择、插入、希尔排序四种算法,其实这四种算法各有好坏,比如前三种实现起来简单,但平均时间复杂度高一些,选择排序无论情况怎么样时间复杂度都是O(n^2),希尔排序算是今天这四种算法里面最快了