What’s Kafka?
官方定义,Kafka是一款开源的消息引擎系统。消息引擎系统是一种规范,利用这种规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递
举个例子:比如系统A发送消息给消息引擎系统(Kafka),系统B从消息引擎中读取A的消息
- 注:Kafka发展到现在是2.0版本了,现在致力于流处理平台,这篇博客讨论的还是Kafka消息引擎,对于Kafka的流处理,可以自行google了解下
Kafka能解决什么
1、 异步处理
2、 流量控制
3、 服务解耦
4、 削峰填谷:保护下游系统,防止下游系统被压垮
Kafka传输消息的两种方式
1、 点对点:生产生产的消息只能被一个消费者消费
2、 发布/订阅模型:生产者生产的消息,被多个订阅的消费者消费
Kafka中的术语
先来看一张图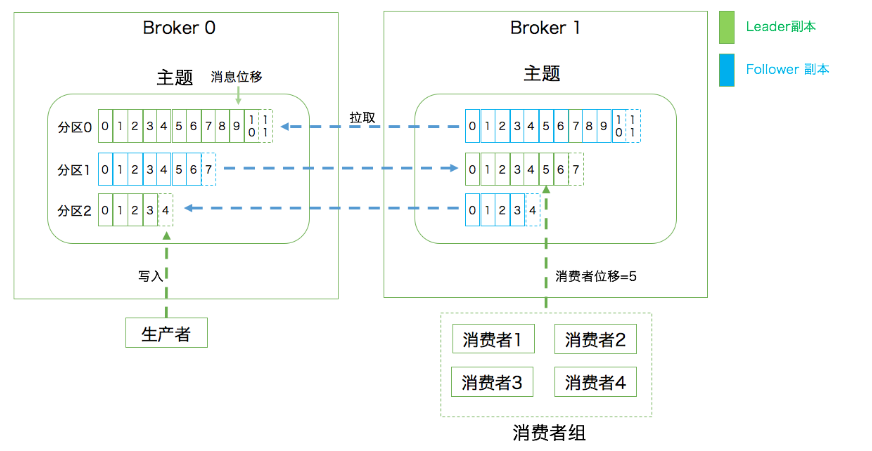
1、 Record(消息):主要是指发送到Kafka,Kafka处理的对象
2、 Broker:你可以简单的理解,一个Broker就是一个Kafka进程(如果你一台服务器运行多个Kafka,那就代表有多个Broker),一个Kafka集群可以有多个Broker组成,Broker负责接受消息和处理客户端发送过来的请求,以及对消息进行持久化。
3、 Topic(主题):发布订阅的对象,你可以为每个业务、每个应用甚至每类数据都创建专属的主题(比如,商品系统跟订单系统需要消息通信,那么你可以在Kafka上创建一个Topic名字叫order_good_topic,两个系统同时指定这个topic就可完成通信)
4、 Producer(生产者):向主题发送消息的客户端程序,生产者可以不断地向一个或多个主题发送消息
5、 Consumer(消费者):订阅这些主题的客户端程序,消费者可以同时订阅多个主题
6、 Replica(副本):相当于备份。Kafka中同一条消息能够被拷贝到多个地方一提供数据冗余,这些地方就是副本。
7、Leader Replica(领导者副本):对外提供服务
8、Follower Replica(追随者副本):被动地追随领导者副本,不能与外界进行交互
- 你可能会有这样的疑惑,竟然追随者副本不能对外提供,只是类似一种备份的作用,那么也就是说只有一个Kafka集群里面,只有一台主Broker进行读写请求的响应,而一台Broker肯定不能积累太多消息,并且所有请求都集中到一台Broker,那肯定会挂,Kafka不能做到横向扩展,这也太cai了吧。别急,分区Partition的出现就是为了解决这种情况
9、Partition(分区):这是个很重要的概念!为了解决伸缩性问题,防止领导者副本积累了太多的数据以至于单台Broker机器无法容纳。我们可以把数据分割成多份保存到不同的Broker上。分区机制指将每个主题划分成多个分区,每个分区是一组有序的消息日志,生产者生产的数据只会被发送到一个分区中。上面的图中,有两台Broker,同一个主题中有3个分区,两个Leader副本(绿色的)在Broker0,一个Leader副本在Broker1,这样的读写消息会分布在两台机器上。这里特别指出,同一个分区中的数据时有序的,什么意思呢?比如你发送三条消息——>1,2,3。那么Kafka接受到这三条数据可能存在不同的分区上,这样消费的顺序可能不是1,2,3(不同分区可以并发消费),如果这三条消息都放在了同一个分区比如分区0,那么消费的时候顺序就一定是1,2,3
10、 Offset(消息位移):向分区写入消息时,每条消息在分区中的位置消息由位移(Offset)的数据来表征
11、 Consumer Offset(消费者位移):记录消费者消费消息的进度,每个消费者都有自己的消费位移
12、 Consumer Group(消费者组):多个消费者实例可以组成一个组,共同消费同一个Topic下的多个分区以实现高吞吐,默认情况下一个分区只能被一个消费者消费
13、 Rebalance(重平衡):前面说一个分区只能被一个消费者消费,如果消费者挂了或者新增加了一个分区,那么就要把这个分区分配给其他消费者,这时需要重平衡操作
Docker运行Kafka
我们在Docker中装个Kafka玩一下,首先编写docker-compose.yml文件
docker-compose.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
depends_on: [ zookeeper ]
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_CREATE_TOPICS: "test:1:1"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
上述运行文件,运行一个Zookeeper和一个Kafka实例,如果需要配置一个Kafka集群,需要添加多个kafka实例,指定不同的端口
运行kafka
1 | docker-compose.exe start |
- 注意:需要安装docker-compose,并且运行时是在docker-compose.yml文件路径下,这样才能加载配置文件

这样kafka就运行了
运行Kafka生产者和消费者
1 | 进入容器 |


可以看到通过生产者向test的topic生产一条数据,消费者就可在topic中消费一条数据
Kotlin代码实现生产者和消费者
引入依赖1
2
3
4
5<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.0</version>
</dependency>
生产者
1 | fun main(args: Array<String>) { |
Java或者Kotlin实现的客户端,在发送消息前都是要对消息实现序列化的,这样能提高传输的效率
上面代码的两种发送方式,一种是有带Callback一种是没有带Callback的,在日常工作使用中,建议带上Callback,这样当Kafka发生异常时,方便于我们通过日志追踪
消费者
1 | fun main(args: Array<String>) { |
同生产者一样,也是需要序列化消息,这里也可以通过添加一个group.id参数,来指定对应的消费者群组
轮询的重要性
Consumer消费者通过轮询的方式监听消息,轮询还有其他重要作用,除了监听消息,还有群组的协调、分区再平衡、发送心跳和获取数据
consumer.poll就是发送轮询的重要方法,里面的参数,指定一个超时时间,用于控制poll的阻塞时间,它会在指定的毫秒内一直等待broker返回数据
而且poll方法返回的是一批数据,这种批量操作有很高的吞吐率
生产者的分区机制
这里我们聊聊分区机制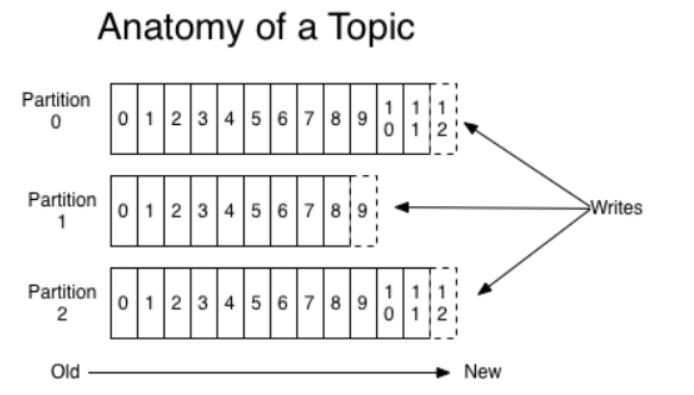
Kafka中消息的组织形式:主题->分区->消息,主题下的每条消息都只会被保存在某个分区下,不会在多个分区中保存多份
为什么要分区
前面已经讲过,主要是为了提供负载均衡能力,或者说为了实现系统的可伸缩性(Scalability)
除此之外,还有实现业务级别的消息顺序
Kafka的分区策略
1、 轮询(默认的策略)
Round-robin策略,也叫做顺序分配。轮询策略具有非常优秀的负载均衡表现,能保证消息最大限度的被平均分配到所有分区上
2、 随机
Randomness策略,随意地将消息放置到一个分区上1
2
3# 实现伪代码
List<PartitionInfo> partitions = cluter.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
3、 按消息键保序策略
Key-ordering策略,指定相同的可以存储相同的分区里面(hash),这个key可以是客户代码,部门编号后者业务ID等,这个功能对我们非常有用,如果我们对消息的顺序保证有严格要求时,可以指定此策略,因为我们前面讲过,同一个分区下的消息是有序的1
2
3# 实现伪代码
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode())%partitions.size());
Kafka默认分区策略同时实现了两种策略:如果指定了key,那么可以默认实现消息键保序策略;如果没有指定key,则使用轮询策略
4、自定义策略
通过实现org.apache.kafka.clients.producer.Partition接口来自定义分区策略
消费者
聊完生产者,我们来聊聊消费者
消费者组
前面我们说过,同一个消费者组订阅同一个topic,该topic中的每一条消息只会被消费者组中的一个消费者消费,每个消费者消费一个分区
如果只有一个消费时,它就会消费topic下的所有分区(这时单个消费者线的消费速度可能跟不上生产速度)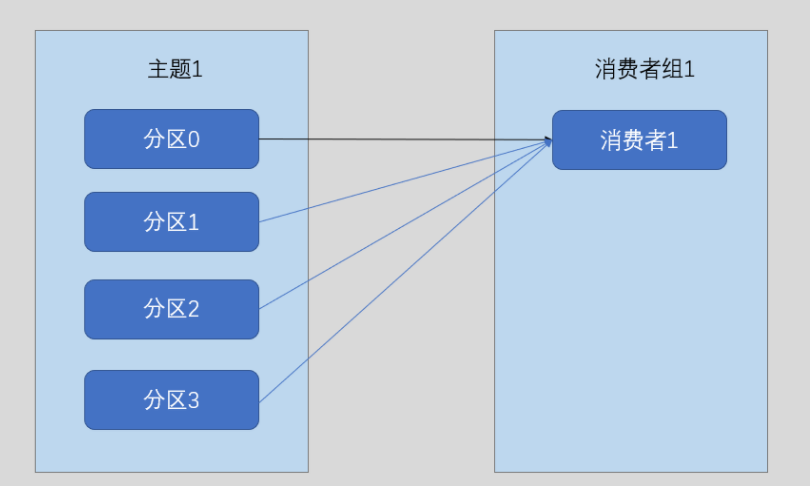
所以最好的方案就是每个分区都有一个消费者线程,提高吞吐量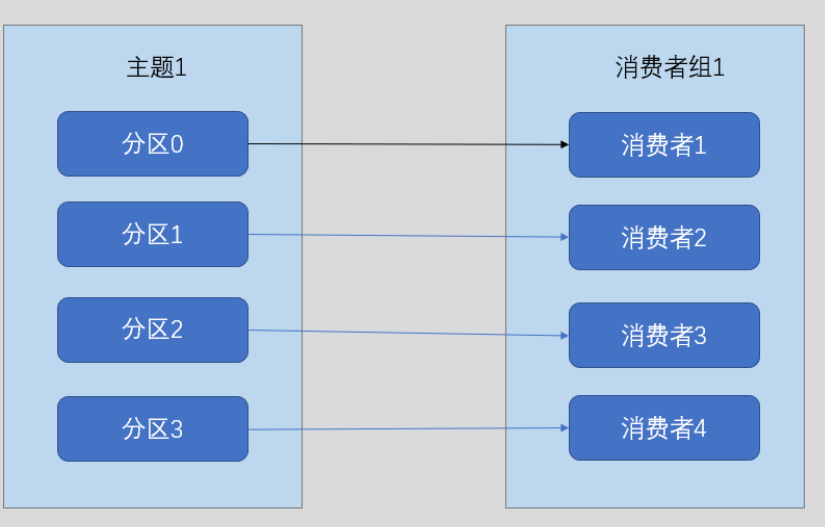
但是也不能让消费者的线程数大于分区数,这样只会让多出的消费者做无用功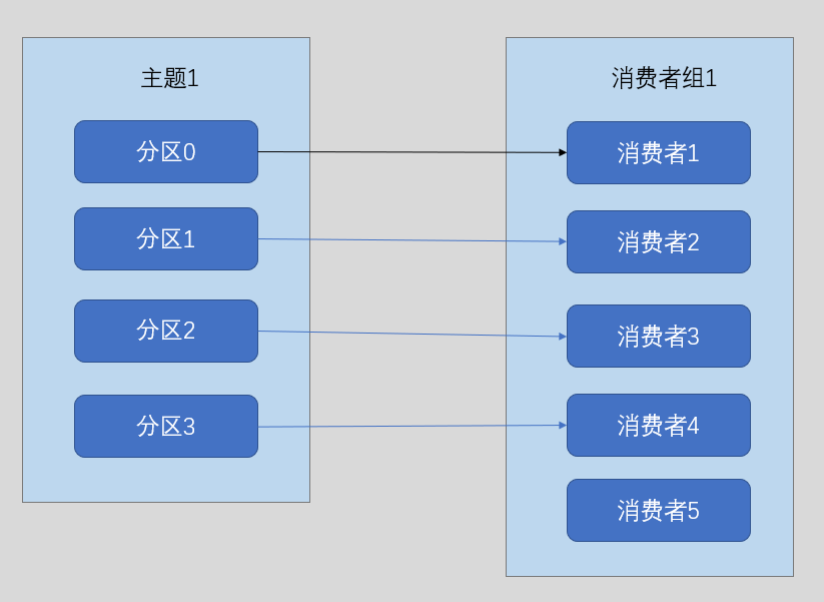
如上图,消费者5没有获得分区的消费,一直做无用功
多个消费者组之间互不影响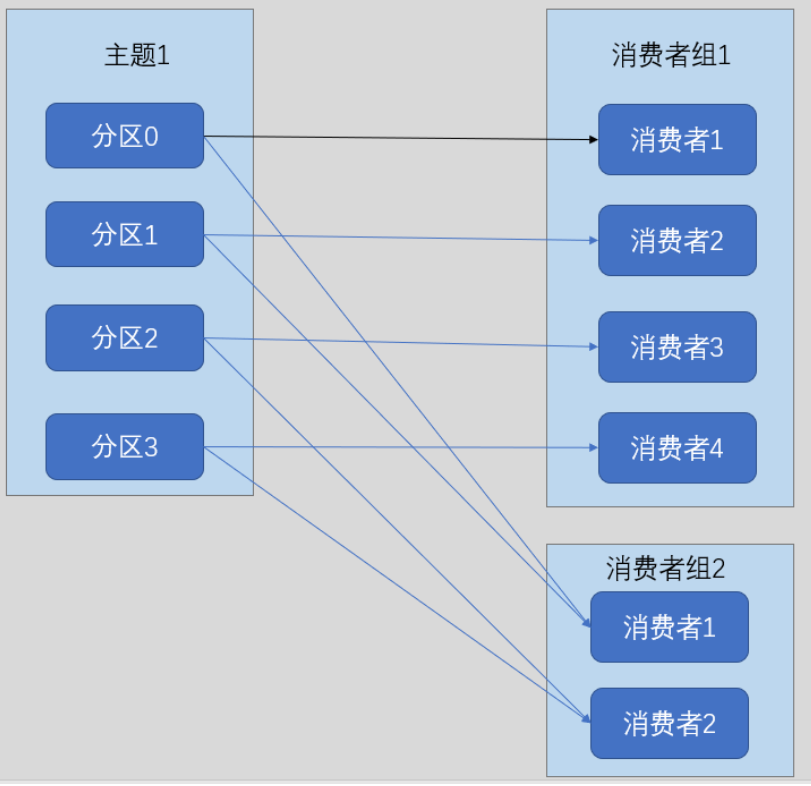
互不影响的底层实现是通过消费者位移实现
再平衡
1、 当一个消费者崩溃或关闭(不可用)时,此时会发生分区重新分配
2、 当一个消费者新加入消费者组时(消费者数小于分区数)时,此时会发生分区重新分配
3、 当增加一个新的分区是,此时也是会发生分区重新分配
缺点和危害:
1、 当发生分区重新分配时,消费者无法读取消息,造成整个群组不用
2、 当分区被重新分配时给另一个消费者时,消费者当前的读取状态可能会丢失
对于第二种情况,在代码层面是可以避免的,我们可以实现一个Kafka再分配监听器,当发生再平衡时,触发函数,在consumer中提交目前已经完成消费的消息偏移1
2
3
4
5
6
7
8
9
10
11
12
13private class Handle implements ConsumerRebalanceListener {
/**
* 重新分配分区之前,消费者停止读取消息之后
*/
public void onPartitionsRevoked(final Collection<TopicPartition> partitions) {
System.out.println("Lost partitions in rebalance.Committing current offsets:"+ConsumerWithListener.this.currentOffsets);
}
public void onPartitionsAssigned(final Collection<TopicPartition> partitions) {
}
}
通过实现ConsumerRebalanceListener接口可完成对再平衡发生的监听
分配分区的过程
Broker端会有一个群组协调器,当一个新的消费者加入时,会向该协调器发送一个JoinGroup请求。第一个加入群组的消费者成为群主,群主有三个功能:1、能够从协调器获取当前所有的成员列表(活跃的消费者);2、根据成员列表,将分区平均分配;3、分配完毕后,将分区情况发回给协调器;
每个消费者只能看到自己的分配信息,只有群主知道所有消费者的分配信息。这些过程只有在再平衡时发生
Kafka如何实现消息交付的可靠性
有这么个问题:如何保证生产者不会重复发送消息,比如因为网络抖动,生产者发送消息失败,等网络好了以后,生产者重复发送了消息,这会出现消费者重复消费的情况
Kafka提供了三种承诺:
1、 最多一次(at most once):消息可能会丢失,但绝不会被重复发送
2、 至少一次(at least once):消息不会丢失,但可能会被重复发送(默认)
3、 精确一次(exactly once):消息不会丢失,也不会被重复发送
Kafka做到精确一次的技术实现
Kafka使用分别使用两种技术实现:幂等性和事务
幂等性(Idempotence)
在配置Kafka的生产者,可以加上该参数1
props.put("enable.idempotence", true);
这种幂等性跟Web实现幂等性是差不多的,服务端Broker多存一些字段,当Producer发送了具有相同的字段(比如一个随机的ID)消息后,Broker就可以知道这些消息有没有被重复消费
局限性:只能保证某个主题的一个分区上不会出现重复消息,无法实现多个分区的幂等性。而且只能保证同一个会话的幂等性,当服务端重启后,幂等性保证就消失
如果要实现多分区以及多会话的消息无重复保证,就是用事务(Transaction)
事务(Transaction)
Kafka 0.11版本开始引入了对事务的支持
read committed隔离级别,保证多条消息原子地写入到目标分区,能够保证Consumer只能看到事务成功提交的消息
事务型Producer能够保证将消息原子性地写入到多个分区中,要么全部写入成功,要么全部写入失败。所以就算是网络发生异常,那条旧的消息是不会发送的
开启事务型Producer(需要两步):
1、 开启幂等性Idempotence:enabl.idempotence = true
2、 设置Producer端陈述transaction.id
1 | producer.initTransactions(); |
但发生写入失败时,Kafka也会把消息写入到底层日志,Consumer也可能会看到并消费这条消息,不过这也是可配置的,通过配置隔离级别isolation.level参数:
1、 read_uncommitted:这是默认值,Consumer可以读取到Kafka写入消息,不管消息是否被提交
2、 read_committed:表明Consumer只可以读取到事务提交的消息
这里稍微总结一下,Kafka怎么保证生产者不会重复发送相同的消息?
1、通过幂等性Producer,但幂等性Producer有局限性,比如智能保证同一个分区下的幂等性
2、通过事务型Producer,虽然有很好的可靠性保证,但是性能会很差,吞吐量不高