Kafka的协调服务ZooKeeper
简介
ZooKeeper是一个分布式协调服务框架,主要是为了解决分布式集群中,应用系统面对的各种通用一致性问题。ZooKeeper本身就可以部署为一个集群,集群的各个节点之间可以通过选举产生一个Leader,选举遵循半数以上的原则,一般集群需要部署奇数个节点,简单的说ZooKeeper是一个高可用、高可靠的一致性存储系统
作用
- 提供分布式的存储系统
- 数组的组织方式类似于UNIX文件系统的属性结构
- 提供永久节点和临时节点,如果创建临时节点的客户端与ZooKeeper集群失去连接,临时节点就会消失
- ZooKeeper负责检测所有客户端的心跳
- Watcher机制,通过订阅ZNode状态的变化获取通知机制,一旦订阅ZNode或者它的子节点状态发生了变化,订阅的客户端立马可以收到通知
- 实现业务集群的快速选举、节点间的简单通信、分布式锁..
Kafka中使用ZooKeeper
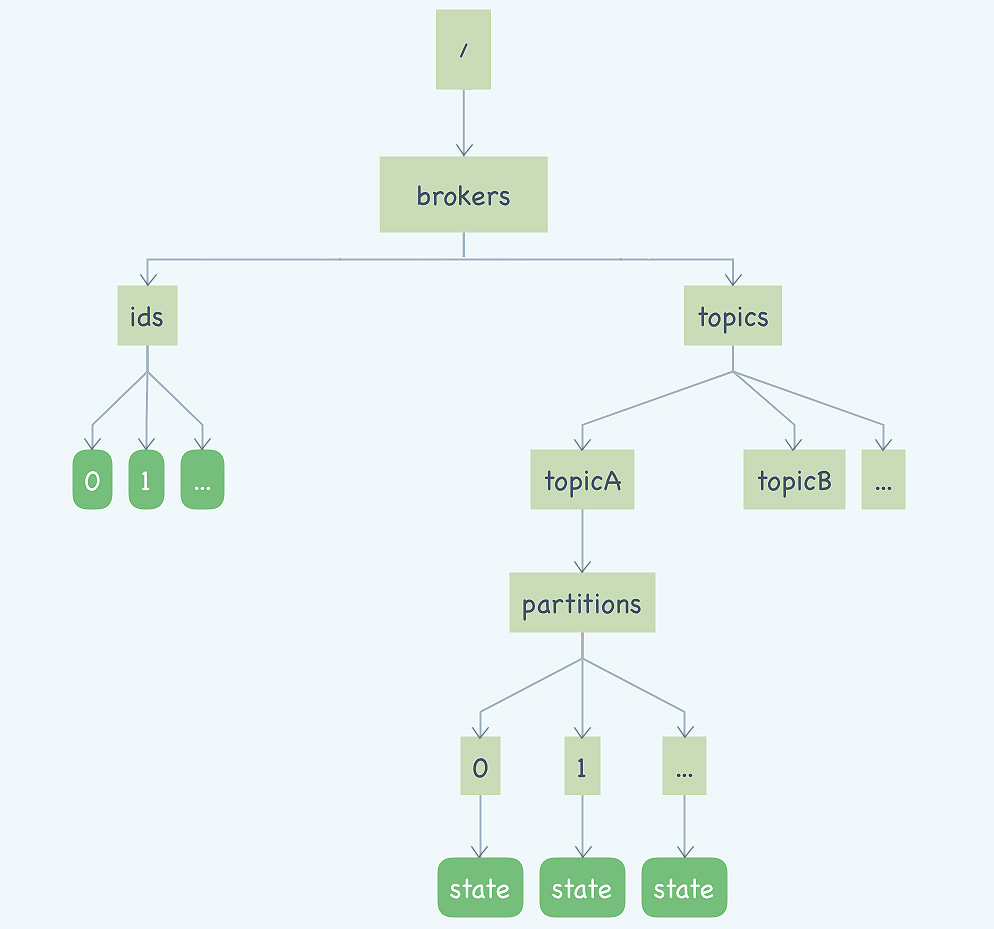
- 注:老版本的Kafka会将消息的消费位置管理也一起存放在ZooKeeper中,当Consumer重启后,能自动从ZooKeeper读取位移数据,从而继续消费。这种设计使得Kafka Broker不要保存位移数据。但是因为ZooKeeper的读写新能问题,不适合高频写操作,后面的版本就改为存放在Broker中,将Consumer的位移数据作为一条条普通的Kafka消息,提交到_consumer_offsets中
保存Kafka的元数据,主要是Broker的列表和主题分区信息两棵树,里面比较重要的数据有:
- 所有主题消息。包括分区信息,比如领导者副本,ISR 集合有哪些副本
- 所有Broker信息。包括当前运行的Broker,哪些正在关闭的Broker
- 所有涉及运维任务的分区。包括当前正在进行Preferred领导者选举以及分区重分配的分区列表
ZooKeeper的一些局限
- 不能让ZooKeeper写入大量数据,在写入几百MB数据后,性能和稳定性都会严重下降
- 不要让业务集群的可用性严重依赖ZooKeeper,防止ZooKeeper集群宕机,业务系统都不可用
控制器组件(Controller)
控制器组件在Kafka中,作用主要是在ZooKeeper的帮助下管理和协调整个Kafka集群,任意一台Broker都能充当控制器角色,但是只有一个Broker能成为控制器,第一个成功创建 /controller 节点的Broker会被指定为控制器
控制器的职责
- 主题管理(创建、删除、增加分区)
- 分区重分配
- 集群成员管理(新增Broker、Broker主动关闭、Broker宕机)
- 数据服务,Controller向其他Broker提供数据服务,控制器上保存了最全的集群元数据,其他所有Broker会定期接收控制器发来的元数据更新请求
控制器故障转移(Failover)
只能有一台Broker充当控制器角色,就存在单点失效(Single Point of Failure)的风险,Kafka为控制器提供了故障转移功能,当运行中的控制器突然宕机或者意外终止,Kafka能够快速地感知到,并立即启用备用控制器来替代之前失败的控制器,该过程自动完成